Вот тут меня спрашивают, а как посчитать R
2. Не знаю, зачем, но почему бы не посчитать. Формула
есть, а заодно и
MAE (среднюю абсолютную ошибку) посчитаем.
Для этого сделаем по-быстрому функцию
Код:
# Функция, вычисляющая R.Sqv и MAE
# (c) Hogfather, 2012
MyInfo<-function(DF,lambda,debug=F){
MyEcdf<-ecdf(DF)
MyLen<-length(DF)
MyKnots<-1:max(knots(MyEcdf))
dfecdf <- data.frame(knots=MyKnots,Fn=MyEcdf(MyKnots))
dfecdf$Fa<-ppois(dfecdf$knots, lambda)
dfecdf$R2<-(dfecdf$Fn-dfecdf$Fa)^2
TSS<-sum(dfecdf$R2)
dfecdf$RR2<-(dfecdf$Fn-mean(dfecdf$Fn))^2
ESS<-sum(dfecdf$RR2)
R2<-1-TSS/ESS
dfecdf$Err<-dfecdf$Fn-dfecdf$Fa
MAE<-mean(abs(dfecdf$Err))*MyLen
print(data.frame(R.Sqv=R2,MAE))
if(debug) print(dfecdf)
plot(dfecdf$knots,dfecdf$Err*MyLen,col="red",xlab="Число букв в слове",ylab="Ошибка аппроксимации, слов",main="Ошибки аппроксимации")
abline(0,0)
}
Скопируем в R, запустим. Дальше достаточно натравить её на наши данные и получить не только результат, но и красивый график.
LT - у нас определено выше, 7.199839 - это полученная в результате лямбда.
Результат:
Код:
> MyInfo(LT,7.199839)
R.Sqv MAE
1 0.999686 191.5201
R
2=0.999686
MAE=191.5201 слов. Вот тут уже именно слов

.
График
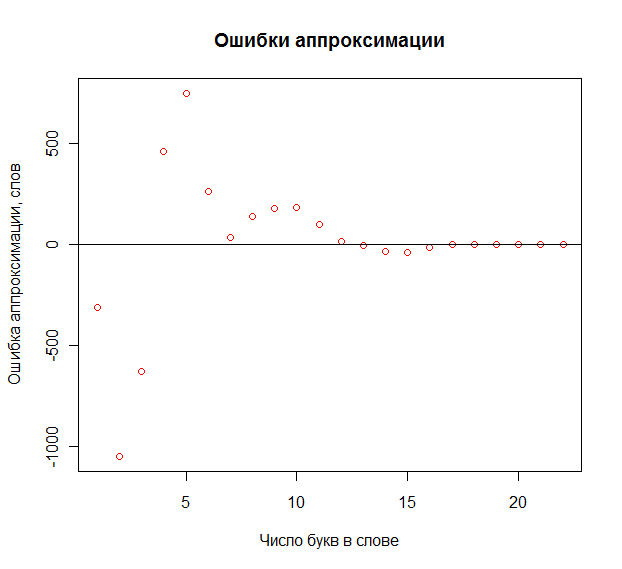
Теперь о R
2. Обратите внимание, что будет если мы чуть изменим лямбду.
Код:
> MyInfo(LT,8)
R.Sqv MAE
1 0.9758058 1950.267
R
2=0.9758058, т.е. вполне годный. А вот MAE увеличилось на порядок (!). Такие дела.
Добавлено через 58 минут
Можно и совсем облениться, если данных много надо обработать, а вводить команды одни те же лень. Пишем функцию, которая делает за нас все.
Код:
# Функция, которая только за пивом не бегает
# (c) Hogfather, 2012
MyInfoPois<-function(DF){
#Подключим библиотеку
require(fitdistrplus)
# Для начала построим красивый график
descdist(DF,discrete = TRUE)
par(ask=T)
DFPois<-fitdist(DF, "pois")
lambda<-DFPois$estimate[[1]]
print(summary(DFPois))
gofstat(DFPois,print.test=TRUE)
plot(DFPois)
# А это уже было ранее. См функцию MyInfo
MyEcdf<-ecdf(DF)
MyLen<-length(DF)
MyKnots<-1:max(knots(MyEcdf))
dfecdf <- data.frame(knots=MyKnots,Fn=MyEcdf(MyKnots))
dfecdf$Fa<-ppois(dfecdf$knots, lambda)
dfecdf$R2<-(dfecdf$Fn-dfecdf$Fa)^2
TSS<-sum(dfecdf$R2)
dfecdf$RR2<-(dfecdf$Fn-mean(dfecdf$Fn))^2
ESS<-sum(dfecdf$RR2)
R2<-1-TSS/ESS
dfecdf$Err<-dfecdf$Fn-dfecdf$Fa
MAE<-mean(abs(dfecdf$Err))*MyLen
print(data.frame(R.Sqv=R2,MAE))
plot(dfecdf$knots,dfecdf$Err*MyLen,col="red",xlab="Число букв в слове",ylab="Ошибка аппроксимации, слов",main="Ошибки аппроксимации")
par(ask=F)
abline(0,0)
}
Результат запуска.
Код:
> MyInfoPois(LT)
summary statistics
------
min: 1 max: 22
median: 7
mean: 7.199839
estimated sd: 2.628829
estimated skewness: 0.519882
estimated kurtosis: 3.143716
Fitting of the distribution ' pois ' by maximum likelihood
Parameters :
estimate Std. Error
lambda 7.199839 0.01175249
Loglikelihood: -123149.4 AIC: 246300.8 BIC: 246309.7
Chi-squared statistic: 445.9628
Degree of freedom of the Chi-squared distribution: 11
Chi-squared p-value: 1.041315e-88
Ожидаю подтверждения смены страницы...
R.Sqv MAE
1 0.999686 191.5198
Ожидаю подтверждения смены страницы...
Ожидание смены страницы, чтобы можно было сохранить график. Для перехода к следующему графику, надо кликнуть по нему мышкой. Несложно, конечно, сразу выводить его в нужный файловый формат, чуть допилить функцию и всё. Как выводить в файл я уже писал.
Картинки повторять не буду. Они все уже приведены.
Лирическое отступление для Дмитрия В. и не только.
Ежу понятно, что вышеописанное никому не нужно, разве что, продемонстрировать возможности R (я себе такую цель ставил). Вообще, прежде чем проводить научное исследование, надо себе поставить цель. Поговорим об этом. У нас есть некие эмпирические данные, в данном случае соответствие длины слов количеству букв. Какие возможны варианты.
1. Нам интересна математическая модель, которая показывает зависимость количества слов в языке данной длины в данном словаре от количества букв в слове. Звучит идиотски, согласитесь.
Во всяком случае, это легко аппроксимируется полиномом или так любимой Дмитрием гаммой (но полином лучше будет). Да, в данном случае мы можем говорить о R квадрате.
Но! В данном случае у нас данные фиксированы. Нельзя добавлять или убавлять слова, поскольку это рушит нашу модель. Случайная выборка из словаря рушит всё напрочь! И модель не выполняет своей функции -- не объясняет закономерность.
2. Нам интересна закономерность, описывающая частотное распределение слов по длине. Тогда мы говорим о дискретном стохастическом процессе, причем нас интересуют именно вероятности и мы подгоняем не только дифференциальную, но и интегральную функцию распределения. Тогда ошибки считать -- заниматься профанацией. Для каждой выборки они будут свои. Задача стоит выбрать лучшее из возможных плохих вариантов. Тут в нас начинают работать информационные критерии AIC и BIC и мы выбираем из нескольких распределений лучшее. Если бы сошелся Хи-квадрат, было бы вообще счастье. Но, к сожалению, счастье бывает только в учебниках. В жизни приходится мучатся. Где-то так.
Никто, правда нам не мешает сказать, что для всего словаря Эр. квадрат такой-то, а средняя абсолютная ошибка такая-то (причем для дифференциальной и интегральной функции они будут разные, гы). А смысл?
Другой вариант, бутстреппинг. Т.е. случайная выборка, пересчет Эр квадрат и ошибки для каждого случая и отображение этого на двумерном графике. Но это чересчур брутально.
Надеюсь, что несильно наврал, а если и наврал меня поправят.