Цитата:
Сообщение от Paul Kellerman
Имеет тест на 45 вопросов по 4 варианта ответа в каждом. Только один вариант верный.
Тест разбит на 3 блока по 15 вопросов. За правильные ответы на вопросы из 1-го блока
начисляется 1 балл, из 2-го блока - 2 балла, из 3-го блока - 3 балла, и соответственно,
максимальный балл, который можно набрать = 90. Определить вероятность сдачи теста,
тыкая ответы наугад, при условии, что для успешной сдачи нужна набрать минимум 61.
|
Итак, вернемся к нашим баранам. Собственно, решение задачи основано на знании
формулы Бернулли и понимания
биноминального распределения.
Функция вероятности для биноминального распределения в R имеет вид
dbinom(x, size, prob, log = FALSE), остальные связанные функции:
pbinom(q, size, prob, lower.tail = TRUE, log.p = FALSE) - функция распределения
qbinom(p, size, prob, lower.tail = TRUE, log.p = FALSE) - квантили распределения
rbinom(n, size, prob) - генерация случайного числа, распределенного по данному закону
где, соответственно: size - число попыток, prob - вероятность удачного исхода
Поэтому задачу:
Цитата:
Сообщение от Paul Kellerman
Вот к примеру есть тупо тест тупо на 45 вопросов тупо по 4 ответа
в каждом, и только один ответ верный. Для положительной оценки
нужно минимум на 31 вопрос ответить верно. Какова вероятность
сдать его, ничего не зная, тупо тыкая наугад ответы?
|
можно решить двумя способами, через сложение устраивающих нас исходов испытания или как разницу между 1 и вероятностью неустраивающих нас результатов, которая равна куммулятивной сумме вероятностей исходов от 0 до 30, что соответствует значению функции распределения pbinom(30, 45, 0.25)
Код:
> sum(dbinom(31:45, 45, 0.25))
[1] 7.527228e-10
> 1-pbinom(30, 45, 0.25)
[1] 7.527228e-10
В MS Excel это считается так:
=1-БИНОМ.РАСП(30;45;0,25;ИСТИНА)
и имеем результат
7,52723E-10
Вооружившись этими немудреными знаниями приступаем к задаче. Здесь у нас существуют возможные варианты исходов от 0 до 90, но поскольку веса у каждого блока в тесте разные, проще прогнать все варианты в цикле и учесть число возможных перестановок, а также вероятность совместного события. Поскольку в данном случае события независимые, то вероятности перемножаем. По сути, мы решаем ту же задачу, только слегка усложненную.
Код:
> # Инициируем переменные
> P<-0 # Переменная для подсчета куммулятивной суммы, как увидим дальше, она лишняя. Просто для явности подсчетов для решения задачи
> Z<-data.frame(X=0:90,y=rep(0,91)) # Здесь мы будем накапливать вероятности для исходо теста 0:90
> for(i in 0:15) for (j in 0:15) for(k in 0:15) { # Перебираем возможные варианты для каждой части теста
+ Z$y[i+2*j+3*k+1]<-Z$y[i+2*j+3*k+1]+dbinom(i,15,0.25)*dbinom(j,15,0.25)*dbinom(k,15,0.25) # считаем вероятность куммулятивно для точки
+ if(i+2*j+3*k>=61) P<-P+dbinom(i,15,0.25)*dbinom(j,15,0.25)*dbinom(k,15,0.25) # считаем для точки
+ }
> Z$cdf<-cumsum(Z$y)
> cat("Ответ на задачу составляет: ",P)
Ответ на задачу составляет: 1.73944e-08
> oldpar<-par(mfrow=c(2,1))
> plot(Z$y~Z$X,main="Функция вероятности f(x)",xlab="x",ylab="f(x)",pch=19,cex=0.8,col="blue")
> points(Z$y[62:91]~Z$X[62:91],cex=0.9,col="red",pch=19)
> text(70,0.02,expression(sum(f[i],i==61,90)==1.73944 %*% 10^{-8}))
> plot(Z$cdf~Z$X,main="Рапределения F(x)",xlab="x",ylab="f(x)",pch=19,cex=0.8,col="blue")
> abline(h=Z$cdf[61],v=60,col="darkgrey",lty=2)
> points(Z$cdf[61]~Z$X[61],cex=0.9,col="red",pch=19)
> par(oldpar)
> # Собственно, как и было сказано выше, вероятности также можно посчитать как:
> 1-Z$cdf[61] # 1-F(60); 61, а не 60, потому как нумерация в массиве начинается с 1
[1] 1.73944e-08
> sum(Z$y[62:91]) # sum(f(t),t = 61...90)
[1] 1.73944e-08
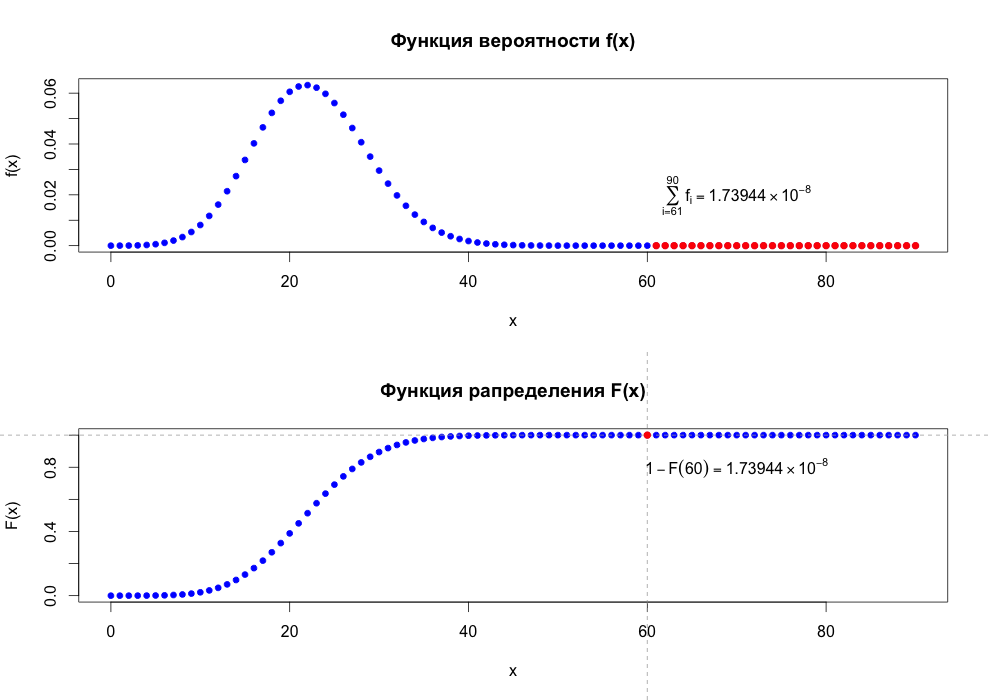
Обращаю внимание, что функции дискретны, поэтому рисовать их сплошной линией -- фигня и моветон.