|
|
 22.03.2013, 20:50
22.03.2013, 20:50
|
#31 |
|
Platinum Member
Регистрация: 22.07.2010
Адрес: Санкт-Петербург
Сообщений: 3,304
|
1. Трансформация данных
Возник вопрос: как преобразовать данные в R на манер сводных таблиц Excel. Вопрос был решен, но в процессе открыты для себя два полезных пакета, о которых хотелось бы рассказать. Пакет reshape2 - позволяет агрегировать данные на манер Excel. На сайте http://www.r-statistics.com/tag/aggregate/ есть неплохой разбор его возможностей. Основная идея должна быть понятна вот из этой схемы (кликабельна).  Второй пакет -- sqldf. Позволяет писать прямо в коде SQL запросы к данным в синтаксисе SQLite. Привожу простой код, который решает одну и ту же задачу с использованием двух этих пакетов. Имеются данные по весу кошачьих сердец, кошачьих тушек и пола (Пакет MASS данные cats), Попробуем найти для каждого пола число измерений и средний вес тушки. Напишем тестовый пример, который бы в цикле 1000 раз пытался решить эту задачу и посчитаем затраченное время. Возможное решение. Код:
> library(MASS)
> library(sqldf)
> library(reshape2)
>
> head(cats)
Sex Bwt Hwt
1 F 2.0 7.0
2 F 2.0 7.4
3 F 2.0 9.5
4 F 2.1 7.2
5 F 2.1 7.3
6 F 2.1 7.6
>
> # Первый тест тест. Библиотека sqldf
> x<-Sys.time()
> for(i in 1:1000) z<-sqldf("select Sex,count(*) as cnt,avg(Bwt) as Avg_Bwt from cats group by Sex")
> y<-Sys.time()
> y-x
Time difference of 19.61596 secs
> z
Sex cnt Avg_Bwt
1 F 47 2.359574
2 M 97 2.900000
> # Второй тест. Библиотека reshape 2
> id<-1:nrow(cats)
> mcats<-melt(cbind(id,cats),id=c("id","Sex"))
> x<-Sys.time()
> for(i in 1:1000) {
+ df1<-dcast(subset(mcats,variable == "Bwt"),formula=Sex~variable,length)
+ df2<-dcast(subset(mcats,variable == "Bwt"),formula=Sex~variable,mean)
+ merge(df1,df2,intersect="Sex")
+ }
> y<-Sys.time()
> y-x
Time difference of 12.49125 secs
> z
Sex cnt Avg_Bwt
1 F 47 2.359574
2 M 97 2.900000
Во втором примере также показано объединение двух таблиц по ключевому полю с использованием команды merge, поскольку команда cast не позволяет агрегировать сразу по двум функциям (может и позволяет, но я не умею). Такие дела (с). 2. Графы в GNU R Рассматривая интересные библиотеки в R можно упомянуть о возможности строить графы с помощью библиотеки igraph. Простой пример кода. Пытаемся построить граф связей на портале аспирантов (фрагмент). Код:
library(graph)
# Заполнем фрейм парами данных
left<-rep("Hogfather",16)
right<-c("Alextiger","caty-zharr","Dukar","Ink","IvanSpbRu","Martusya","osmos","saovu","Seta","Uzanka","Vica3","Димитриадис","Дмитрий В.","Домохозяйка","море","Степан Капуста")
left1<-rep("Степан Капуста",2)
right1<-c("Hogfather","Ink")
left<-c(left,left1)
right<-c(right,right1)
left1<-rep("море",10)
right1<-c("agasfer","Alextiger","bugo","fazotron","Hogfather","Ink","IvanSpbRu","Maksimus","Martusya","osmos")
left<-c(left,left1)
right<-c(right,right1)
myData<-data.frame(left,right)
# Формируем и строим граф
g<-graph.data.frame(myData,directed=F)
plot(g,vertex.label.cex=0.8,vertex.label.dist=1,vertex.size=10)
Нужно или нет, решать вам, но если надо рисовать серьезные графы, то рекомендую сперва глянуть в сторону graphviz. Очень кошерная и мощная штука. |

|

|
| Реклама | |
|
| |
|
10.06.2013, 15:27
|
#32 |
|
Platinum Member
Регистрация: 22.07.2010
Адрес: Санкт-Петербург
Сообщений: 3,304
|
Вышла книга. Шитиков В.К., Розенберг Г.С. Рандомизация и бутстреп: статистический анализ в биологии и экологии с использованием R. - Тольятти: «Кассандра», 2013. - 289 с.
Ссылка ведет на Интернет-версию на сайте авторов. |
|
---------
DNF is not an option
|
|
|
|
|
|
26.06.2013, 15:23
|
#33 | |||||
|
Platinum Member
Регистрация: 22.07.2010
Адрес: Санкт-Петербург
Сообщений: 3,304
|
Цитата:
Цитата:
Код:
FileList<-dir("Data_R",pattern = "*.txt", full.names = TRUE, ignore.case = TRUE, include.dirs =TRUE)
MyResult<-data.frame()
for(FileName in FileList)
{
TempTable<-read.table(FileName,sep=" ")
TempTable$FileName<-FileName
MyResult<-rbind(MyResult,TempTable)
}
Цитата:
Добавлено через 36 минут С другой стороны, данных много, поэтому возможно удобнее будет загнать в базу данных SQLite (см. выше о работе в R) и использовать срезы оттуда. Модифицируем чуть-чуть вышеприведенный код Цитата:
Добавлено через 49 минут Цитата:
Код:
set.seed(666) age <- 1:10 y.low <- rnorm(length(age), 150, 25) + 10*age y.high <- rnorm(length(age), 250, 25) + 10*age plot(age,y.high,type = 'n', ylim = c(100, 400), ylab = 'Y Range', xlab = 'Age (years)') lines(age, y.low ) lines(age, y.high) polygon(c(age, rev(age)), c(y.high, rev(y.low)), col = "lightblue", border = NA) # Второй график, чтобы поржать y.low <- rnorm(length(age), 150, 25) + 10*age y.high <- rnorm(length(age), 250, 25) + 10*age lines(age, y.low, col = "green" ) lines(age, y.high, col = "green") polygon(c(age, rev(age)), c(y.high, rev(y.low)), col = "green", border = NA) Последний раз редактировалось Hogfather; 26.06.2013 в 15:05. |
|||||
|
---------
DNF is not an option
|
||||||
|
|
|
|
18.10.2013, 18:18
|
#34 |
|
Gold Member
Регистрация: 16.04.2012
Сообщений: 1,218
|
Hogfather,
а в R можно оценивать GARCH модели с разными распределениями ошибок? а оценивать Stochastic volatility models с разными распределениями? Или самим код надо писать? ЗЫ. А что-то типа фильтра Калмана там есть? |
|
|
|
|
18.10.2013, 18:59
|
#35 | |||
|
Platinum Member
Регистрация: 22.07.2010
Адрес: Санкт-Петербург
Сообщений: 3,304
|
Цитата:
Пример из книжки, упомянутой ниже Код:
library(fGarch)
data(bmw,package="evir")
bmw.garch_norm = garchFit(~arma(1,0)+garch(1,1),data=bmw,cond.dist="norm")
options(digits=3)
summary(bmw.garch_norm)
options(digits=10)
x = bmw.garch_norm@residuals / bmw.garch_norm@sigma.t
n=length(bmw)
grid = (1:n)/(n+1)
fitdistr(x,"t")
par(mfrow=c(1,2))
qqnorm(x,datax=T,ylab= "Standardized residual quantiles",
main="(a) normal plot",
xlab="normal quantiles")
qqline(x,datax=T)
qqplot(sort(x), qt(grid,df=4),
main="(b) t plot, df=4",xlab= "Standardized residual quantiles",
ylab="t-quantiles")
abline( lm( qt(c(.25,.75),df=4)~quantile(x,c(.25,.75)) ) )
bmw.garch_t = garchFit(~arma(1,1)+garch(1,1),cond.dist="std",data=bmw)
options(digits=4)
summary(bmw.garch_t)
Рекомендую почитать книжку Statistics and Data Analysis for Financial Engineering. Я купил и мои волосы теперь чистые и шелковистые. Цитата:
Цитата:
http://cran.r-project.org/web/packages/FKF/index.html Статья по теме http://www.jstatsoft.org/v39/i02/paper |
|||
|
---------
DNF is not an option
|
||||
|
|
|
|
18.10.2013, 19:08
|
#36 |
|
Gold Member
Регистрация: 16.04.2012
Сообщений: 1,218
|
Hogfather,
просто огромное спасибо!!!!!!!  пошла изучать пошла изучать
|
|
|
|
|
23.10.2013, 09:00
|
#37 | |
|
Platinum Member
Регистрация: 22.07.2010
Адрес: Санкт-Петербург
Сообщений: 3,304
|
Приобрел неплохую книжку по Data Mining в GNU R, рекомендую.
Пакет rattle предназначен для поиска закономерностях в данных (Data Mining) с помощью регрессионных деревьев, кластерного анализа и метода опорных векторов. В книжке разбирается порядок действий от загрузки данных до интерпретации результатов. Код:
library(rattle) rattle() К сожалению, работает не все. UPD: Появилось сообщение на форуме поддержки. На настоящий момент решение это проблемы выглядит вот так [1] . Вложение со старой функцией удалено, чтобы не смущало. Цитата:
Т.е. есть еще некоторые проблемки с продуктом,а так, в целом, здорово! Последний раз редактировалось Hogfather; 01.11.2013 в 08:48. |
|
|
---------
DNF is not an option
|
||
|
|
|
|
23.10.2013, 22:34
|
#38 |
|
Platinum Member
Регистрация: 22.07.2010
Адрес: Санкт-Петербург
Сообщений: 3,304
|
UPD: Под МакОс rattle категорически отказался работать. Проблемы с GTK+
|
|
---------
DNF is not an option
|
|
|
|
|
|
07.11.2013, 13:48
|
#39 | |
|
Platinum Member
Регистрация: 22.07.2010
Адрес: Санкт-Петербург
Сообщений: 3,304
|
Давненько не брал я в руки шашек. Вот тут задачку придумали, на самом деле весьма интересную с практической точки зрения.
Цитата:
Последний раз редактировалось Hogfather; 08.11.2013 в 08:59. |
|
|
---------
DNF is not an option
|
||
|
|
|
|
08.11.2013, 07:32
|
#40 | ||
|
Gold Member
Регистрация: 25.06.2005
Адрес: F000:FFF0
Сообщений: 1,838
|
Цитата:
Цитата:
Пусть T - дискретная случайная величина, равная количеству набранных баллов (0...90). Функция вероятности случайной величины T: f(t) = P(T=t) Функция распределения случайной величины T: F(t) = P(T<=t) Решение в математической среде Waterloo Maple 15.0. 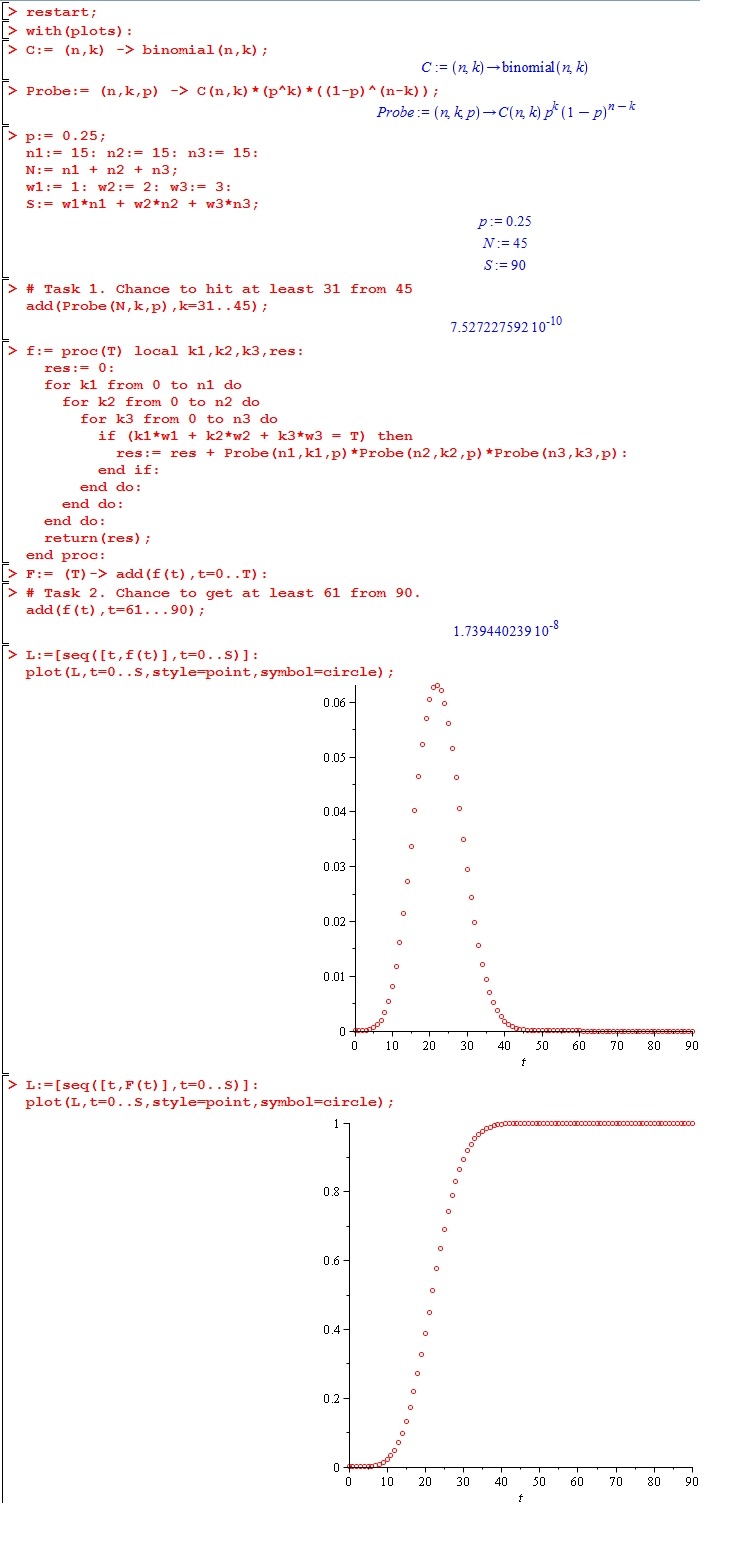
Последний раз редактировалось Paul Kellerman; 08.11.2013 в 10:01. |
||
|
|
|